前言
Deepfakes是一种利用机器学习中的深度学习实现AI视频换脸的技术。这种技术在特定的场合下可以做出非常逼真自然的换脸视频。而DeepFaceLab是众多软件中,安装最简单,使用最方便,更新最快的一款软件。
DeepFaceLab由iperov开源在github, 可直接找到Releases处的下载链接下载对应系统的7Z自解压包,下载完成后解压即可使用。
DeepFaceLab有以下特点:
- 安装方便,只需安装最新版本的显卡驱动即可使用,无需额外安装python和第三方库,DeepFaceLab均已内置并自动调用。
- 尽量使用Win10系统并更新系统补丁,方便使用更新的CUDA版本等功能。
- 最新的DeepFaceLab2版本去除了AMD显卡的支持,因此A卡只能使用DeepFaceLab1版本。
- 目前已经支持多张显卡调用,应尽量使用性能较高的NVIDIA显卡例如RTX2070等,显卡性能越强则训练速度越快,可以训练更高精度的模型。
DeepFaceLab文件夹内的内容如下:
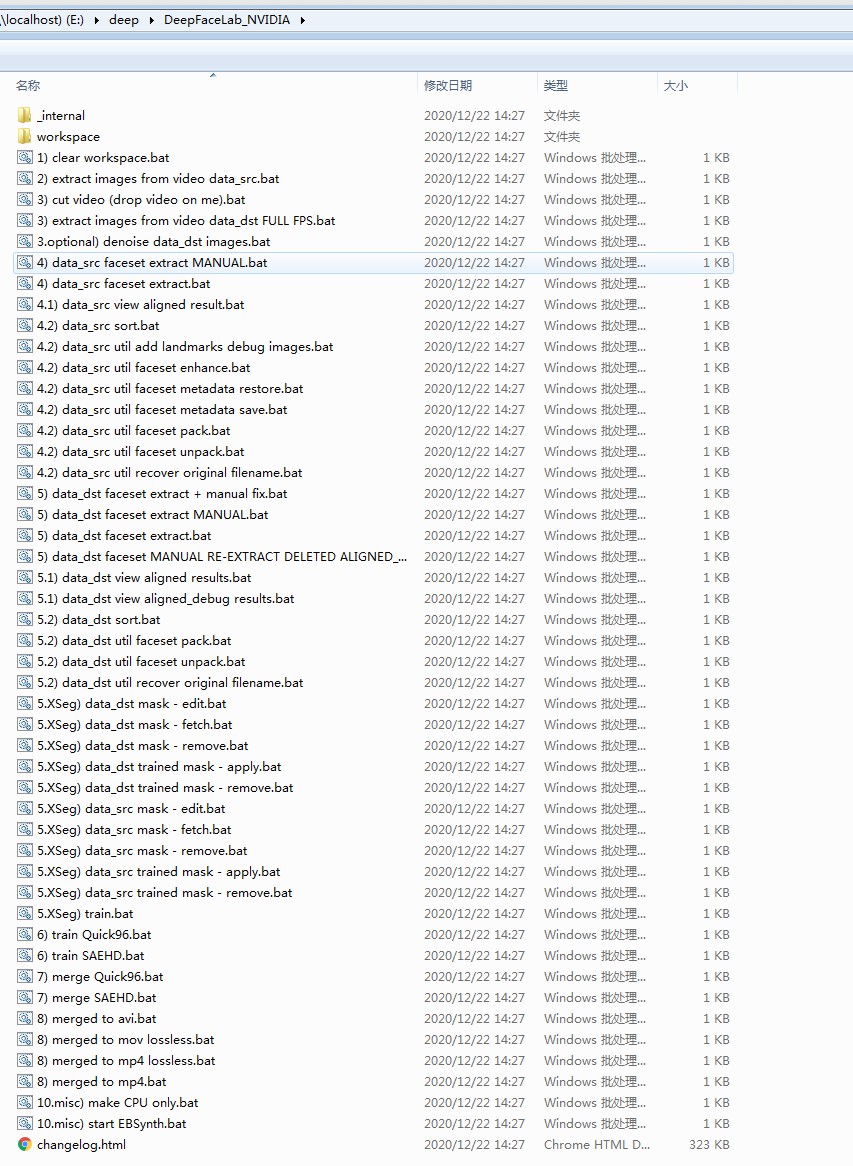
_internal文件夹内为DeepFaceLab的运行环境、py脚本、资源文件等,workspace文件夹内则为工作环境,可将AI换脸的素材放进里面。下方的多个bat文件则是对应不同功能的命令脚本,可根据操作步骤直接双击运行。
DeepFaceLab使用流程主要有以下几步:
- 准备源素材(src)与目标素材(dst)
- 提取源素材(src)与目标素材(dst)的脸部
- 训练脸部遮罩(可选)
- 开始训练模型
- 通过训练好的模型换脸输出
下面进行每一步的详细介绍。
准备源素材与目标素材
对于AI换脸来说,源素材的质量是极为重要的,因为要通过计算将源素材的脸匹配到目标素材上,所以源素材脸部越清晰、不同角度和不同表情的素材越多、脸部光影对比不大,则训练出的模型越精准,能够更好地匹配目标素材。
所以源素材尽量寻找一些近景特写镜头和采访视频等,脸部清晰度尽量在500像素以上。
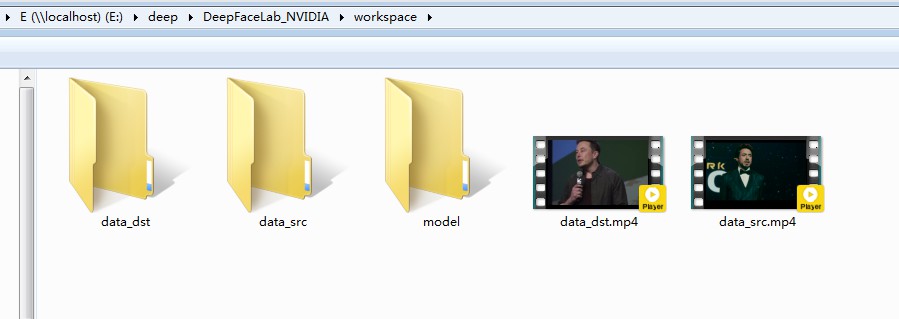
以下是workspace文件夹内的内容,data_src.mp4为源素材,data_dst.mp4为目标素材,而同名文件夹用于存放对应的素材图片序列,model文件夹则用于存放训练出的模型。
图中的两个视频是DeepFaceLab自带的案例,如果自行准备了其他素材可直接改成此名字使用。
首先要将视频提取为图片序列,依次点击执行DeepFaceLab根目录下的2) extract images from video data_src.bat和3) extract images from video data_dst FULL FPS.bat这两个bat脚本。
建议将视频默认提取为png格式,图片质量更高。
提取源素材的图片序列时可以选择FPS,对于较长的视频素材可以适当降低,例如每秒钟视频提取5张或10张图片,避免素材图片太多计算缓慢,保证最后的素材图片数量在1000~10000张左右即可。
从图片素材中提取人脸
为了便于训练,需要将图片素材中的脸部裁切出来,调整为统一的大小,歪斜的脸部角度也得转正。
依次点击执行DeepFaceLab根目录下的4) data_src faceset extract.bat和5) data_dst faceset extract.bat这两个bat脚本。
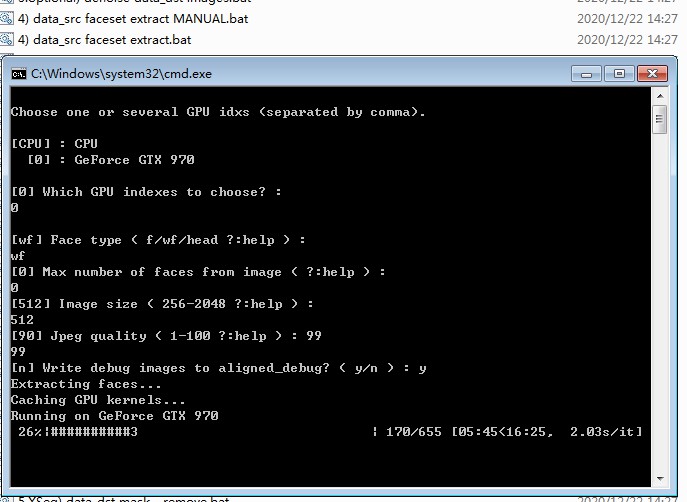
提取人脸时有Face type选项,可以选择f、wf、head三种,脸部截取范围逐渐增大。
执行完毕后,会在对应的data_src和data_dst文件夹内,生成一个aligned文件夹,内部存放的就是从图片素材中提取出的脸部。

脸部提取注意
普通提取像上面这样操作即可,如果视频素材中有多个人脸,默认会全部提取出来放进aligned文件夹中,同一图片不同的脸以图片名字后缀区分。
如果需要限制提取脸部的数量,可以通过设置脚本中的Max number of faces from image这一参数,设置最大提取脸数。
如果已经提取完后再想删除,可以手动删除aligned文件夹中的人脸图片。如果人脸图片混杂在了一起,可以通过DeepFaceLab根目录下的4.2) data_src sort.bat和5.2) data_dst sort.bat将提取出的人脸按照脸部大小、相似度等进行排序,然后再手动删除。
用于训练模型的源素材图片脸部需要尽量清晰,一些因脸部像素低导致的模糊、脸部移动导致的模糊素材脸部,需要删除掉,训练出的模型才能更清晰。同样可以通过4.2) data_src sort.bat将提取出的人脸按照模糊度、运动模糊度等进行排序,再手动删除。
手动提取错误脸部
用于最后合成的目标素材有时会有侧脸角度过大、部分遮挡(例如图片边缘露出半张脸)或者与背景融合等问题,这时往往会导致自动提取脸部错误或者偏移。
这种时候可以到data_dst文件夹中的aligned_debug文件夹中找到人脸定位错误的图片,手动删除。
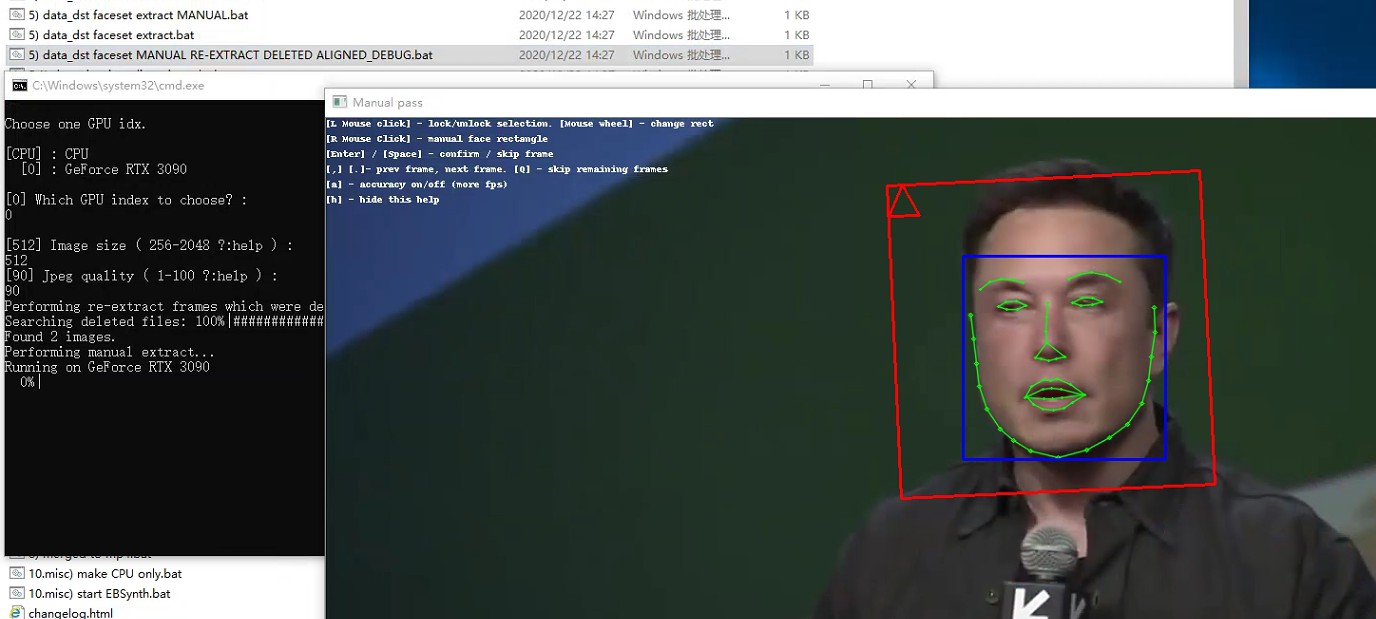
然后运行DeepFaceLab根目录下的5) data_dst faceset MANUAL RE-EXTRACT DELETED ALIGNED_DEBUG.bat脚本,在弹出的窗口中通过鼠标点击手动设置人脸的定位,设置好后点击回车即可修复当前素材图片的脸部提取。
训练脸部遮罩
对于普通的源素材和目标素材这一步可以略过。
但对于一些特殊的情况例如目标脸部有遮挡(例如墨镜、半面罩等)或者想要保留目标脸部的某些特征(例如额头、眼睛、斑痣等)时,默认的换脸会导致源素材的脸和目标的脸部不能匹配,此时就需要训练遮罩。
所谓遮罩就是训练一个可跟随脸部运动的动态范围,此范围内的脸部正常替换,范围外则不做替换。
训练前需要先依次运行DeepFaceLab根目录下的5.XSeg) data_dst mask - edit.bat和5.XSeg) data_src mask - edit.bat脚本,打开XSeg编辑窗口绘制闭合曲线遮罩。
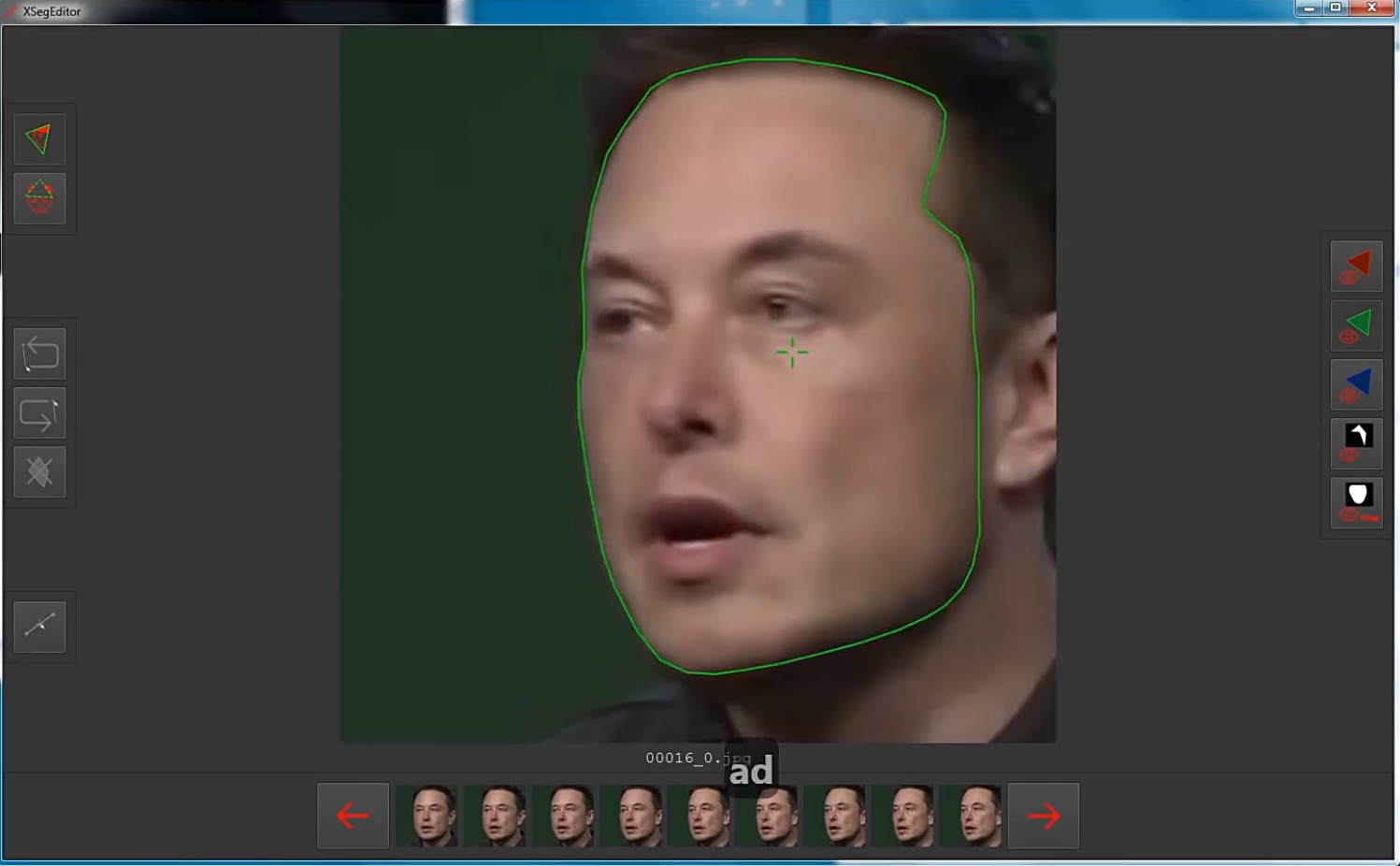
绘画界面如上图所示,实线内是换脸的区域,虚线内是目标素材保留的区域。绘制完当前脸部图片后在下方切换后面其他图片,寻找脸部姿势差别较大的几张图片进行绘制即可。
绘制完遮罩后,运行DeepFaceLab根目录下的5.XSeg) train.bat开始训练,并使用空格(切换预览素材)和p键(刷新预览)观察弹出的预览窗口中的遮罩训练效果。

在遮罩训练差不多后,按回车即可保存遮罩模型停止训练。此时可以运行DeepFaceLab根目录下的5.XSeg) data_dst trained mask - apply.bat和5.XSeg) data_src trained mask - apply.bat脚本,将训练出的遮罩写入素材人脸图片中。
然后可以再打开XSeg编辑窗口,通过窗口右侧最下面的遮罩显示按钮查看每一张图片的遮罩范围是否正确,如果有错误的可以再手动画遮罩,画完重复训练直到得到一个满意的效果。
开始训练模型
准备好人脸后就可以直接运行DeepFaceLab根目录下的训练脚本,根据自身显卡性能,显卡性能较低则运行6) train Quick96.bat,性能足够则运行6) train SAEHD.bat。
前者的Quick96模型只能训练96×96像素大小的人脸模型,并且无法设置高级的自定义参数,显卡的显存只有2G+时可以使用;而后者SAEHD模型则有非常多可自定义的参数,并最大支持640×640像素大小的人脸模型。
下面以SAEHD模型进行说明,运行6) train SAEHD.bat脚本后需要设置很多训练参数,如图所示。
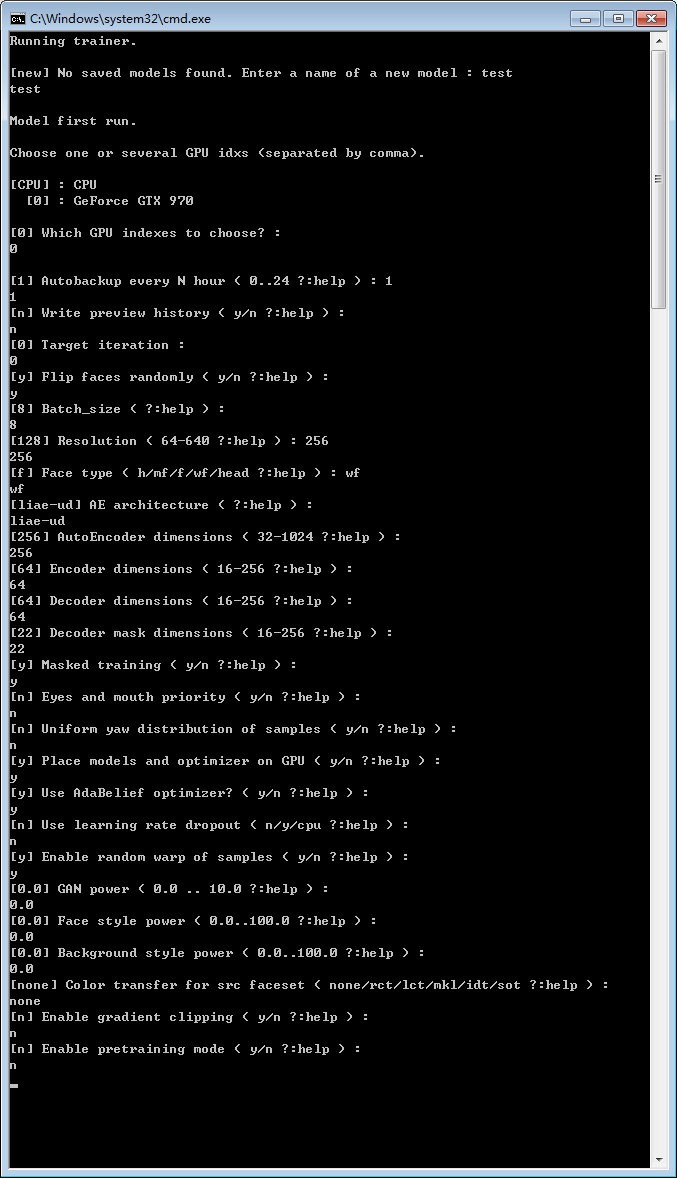
比较常用的有以下参数:
Autobackup every N hour:每隔N小时对模型进行备份,防止意外损坏。
Target iteration:训练迭代次数,默认0即一直训练直到用户手动停止。设置具体值后则迭代数量打倒后自动保存退出。
Flip faces randomly:随机翻转脸部,当素材缺少脸部某一侧素材时可以开启,通过脸部另一侧水平翻转补全这一侧素材,但当素材两侧脸部有明显区别时应该关闭这一选项。
Batch_size:一次迭代训练所选取的样本数,可取值为2的n次方,参数越高,消耗越多显存,单次迭代时间越长,相同迭代次数下效果越好。但参数过高时可能导致训练时卡住,因此需自行测试适合自己硬件的数值。
Resolution:换脸模型像素大小,最大支持640*640像素,数值越大,消耗越多显存,单次迭代时间越长,最终得到的脸部素材越清晰。根据自己需求和显卡性能设置合适数值。
Face type:可选择h(半脸)、mf(中脸)、f(全脸)、wf(整脸)、head(全头),换脸模型的范围依次增大,注意与提取脸部时的Face type参数相配合。其中半脸、中脸、全脸范围如下图所示。

半脸适应性最强,但是有时眉毛换不了,下巴效果较差,比较适合女性换脸。
中脸的面积比半脸大概大了一些,四角弧度比较圆,眉毛也能被完整包含。
全脸是包含了完整的脸颊和下巴,适合处理有胡子的男性脸部。
而整脸则包含了更多的额头区域,可以较好的处理额头的皱纹。
全头则会包含头发,最后的效果已经不是换脸而是换头。
但换脸范围越大,对于脸部素材的质量要求越高,想要达到满意的效果需要更多迭代次数,否则可能导致换脸结果模糊不清、明暗不齐、色彩不均等。
AE architecture:神经网络的模型结构,主要有df和liae两类,带有-ud后缀的效率较高推荐使用。df模型在匹配时不使人脸变形,要求源素材和目标素材脸型尽量相似,要求源素材具有所有所需的脸部角度,否则在侧面轮廓上可能会产生较差的结果;liae模型在匹配时会使人脸变形,可以更好地处理侧面轮廓,并具有更好的颜色光线匹配度。
Masked training:完成了上一步训练遮罩的情况下可以开启,只训练遮罩范围内的脸部模型。
Enable pretraining mode:使用预训练模式。启用后可以通过内置预训练数据集进行预训练,训练到一定程度再修改训练参数关闭预训练使用自己的素材训练,大多数情况下能够得到更好的匹配效果。
其他参数较少使用可直接回车使用默认数值,设置好训练参数后就进入训练计算了,会弹出下图所示的预览窗口。
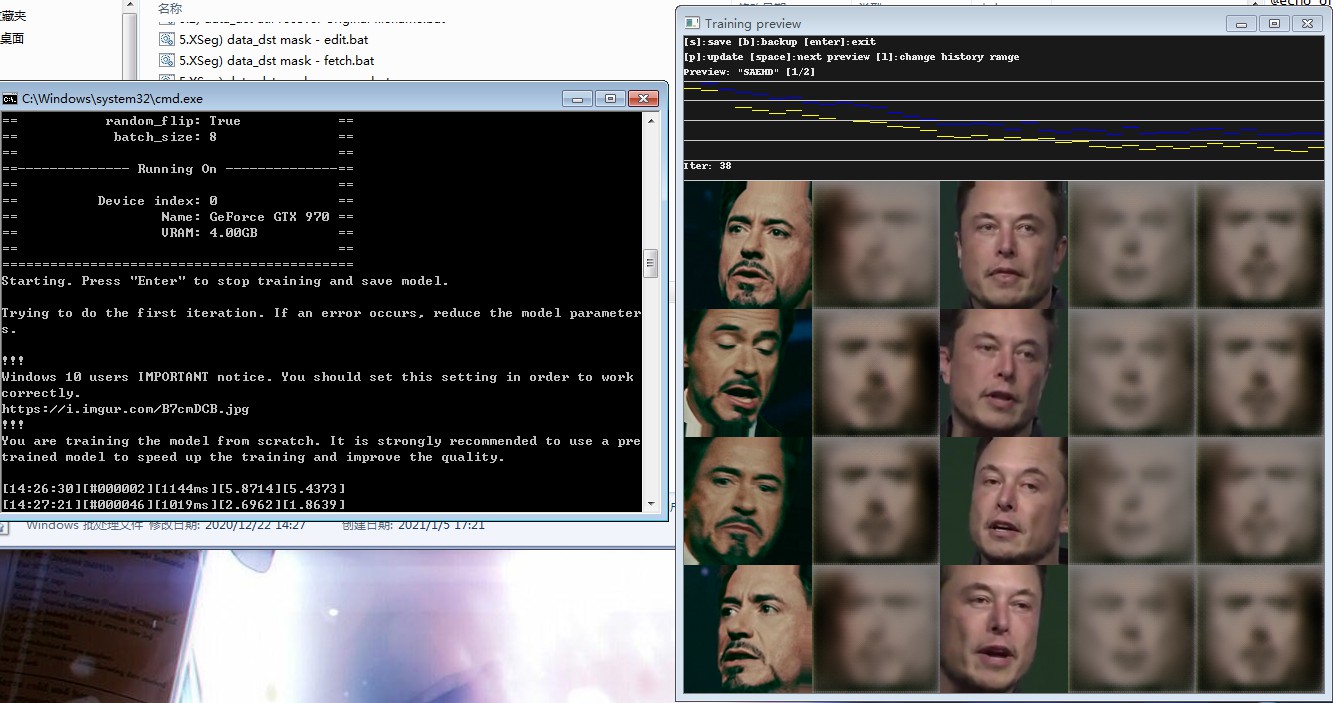
在训练时可以从预览窗口中查看当前效果,和遮罩训练时同样的操作方式,p键刷新预览,s键保存模型,回车保存模型并退出。
训练过程可以随时中止,再运行训练脚本即可从中断位置继续训练,训练进度不会丢失。继续训练时会有一个选项,在2s内按下回车可以修改训练参数再继续训练,2s内不进行操作则以之前的训练参数继续训练。
预览窗口最上方的曲线即为命令行窗口最后一个不断变化的数值随时间的变化,该数值称为loss值,代表了模型与目标素材脸部的差异度,会随着训练时间慢慢降低,对应预览图的慢慢清晰,大多数情况下数值降到0.01~0.02时就足够使用了。
预览窗口中的Iter数值则代表迭代次数,同样的训练素材和参数下,越多的迭代次数会花费越多时间,loss值越小,得到的训练模型效果越好,但随着迭代次数超过一定范围后,loss值很难再降低,训练的模型效果也就达到了极限。
为了获得好的训练效果,训练时间一般较长,十几个小时至一周甚至更长,因此训练模型这一步骤往往被调侃为“炼丹”,而分享的训练好的模型则被称为“仙丹”。
对于用一套素材训练好的模型,也可以套用到其他素材上继续进行训练,很快就能得到较好的效果,这也就是“仙丹”受人追捧的原因。
换脸合成输出
当模型训练到满意后,即可将开始合成步骤,DeepFaceLab根目录下的7) merge Quick96.bat或者7) merge SAEHD.bat脚本(根据上一步骤训练模型的种类选择对应脚本),在Use interactive merger选项中输入y,打开合成窗口,可以通过按键实时查看合成效果。
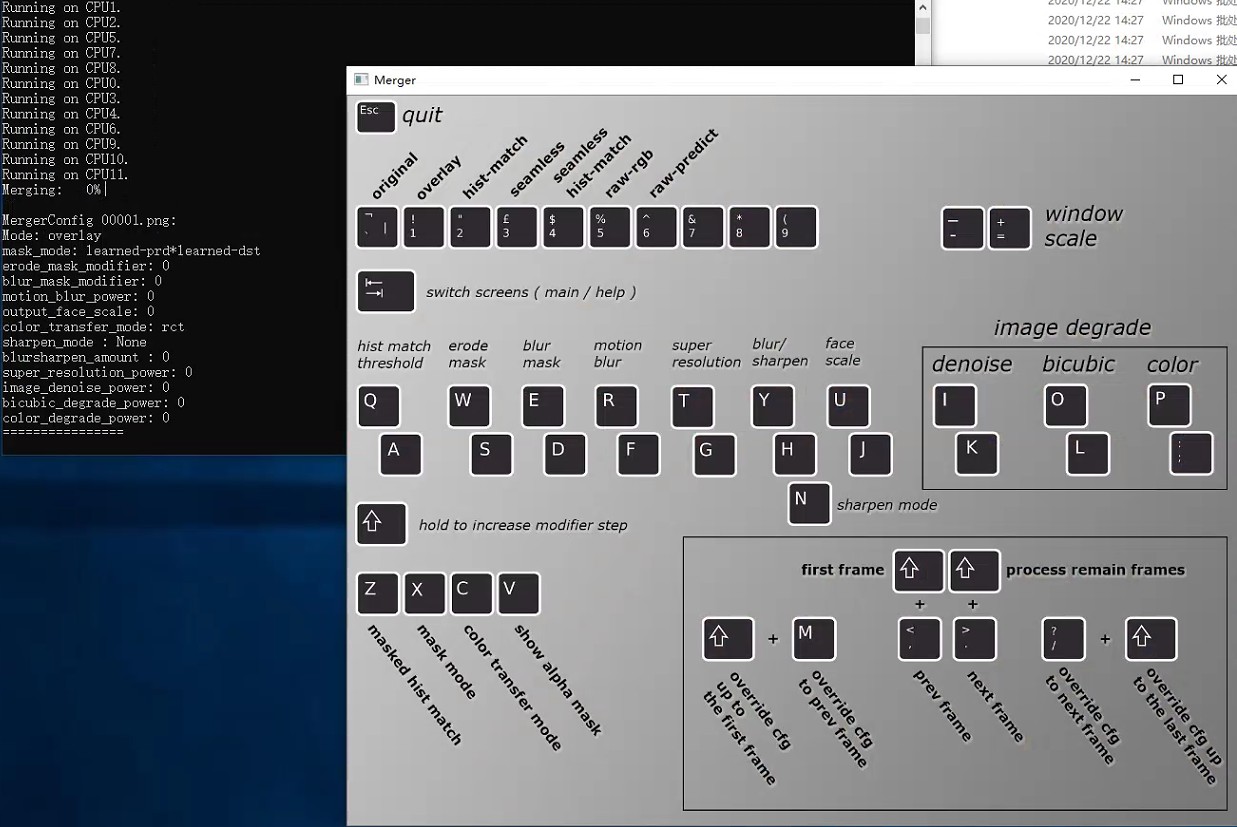
按tab键显示预览效果如下图,命令行窗口中显示当前合成参数,Merger窗口中可查看不同按键的功能和预览合成效果。

合成时比较重要的参数有以下几个:
Mode:合成模式,较常用的有overlay(颜色叠加)和hist-match(直方图匹配)以及seamless(泊松克隆)等。
- overlay(颜色叠加),快捷键1,可以与color_transfer_mode配合使用。
- histmatch(直方图匹配),快捷键2,可以理解为色彩曲线匹配,将源素材脸部色彩明暗调整为与目标素材近似的状态,出现亮斑则适当调小hist match threshold参数。
- seamless(泊松克隆),快捷键3,能够根据目标素材还原一些脸部的光影细节,但目标素材色彩比较杂乱时可能导致颜色不均、闪烁等。
mask_mode:遮罩方式,快捷键x,用于切换换脸范围,如果训练过遮罩可以使用xseg-dst方式,未训练过遮罩可使用learned-dst(自带的预训练遮罩,可修复部分遮挡)或者其他。
color_transfer_mode:颜色叠加方式,快捷键c,一般与overlay模式搭配使用。
erode_mask_modifier:遮罩边缘扩展或收缩,快捷键w、s,用于修改换脸范围。
blur_mask_modifier:遮罩边缘模糊,快捷键e、d,用于换脸和目标脸部融合。
其他还有output_face_scale(放大缩小换脸,快捷键u、j)、super_resolution_power(超分提升细节,快捷键t、g)等,这些参数相互配合能够获得更好的合成效果。
其他快捷键还有tab(切换快捷键显示和合成预览窗口)、+(放大预览窗口)、-(缩小预览窗口)、v(查看遮罩)、<(跳转上一帧)、>(跳转下一帧)、m(跳转上一帧并使用当前合成参数)、/(跳转下一帧并使用当前合成参数)、Shift+<(回到第一帧)、Shift+m(以当前合成参数合成前面所有帧)、Shift+/(以当前合成参数合成后面所有帧)、Shift+>(以当前合成参数合成其他所有帧)。
合成完成后,data_dst文件夹内会出现merged和merged_mask文件夹,里面分别是合成后的图片序列和合成时的脸部遮罩。
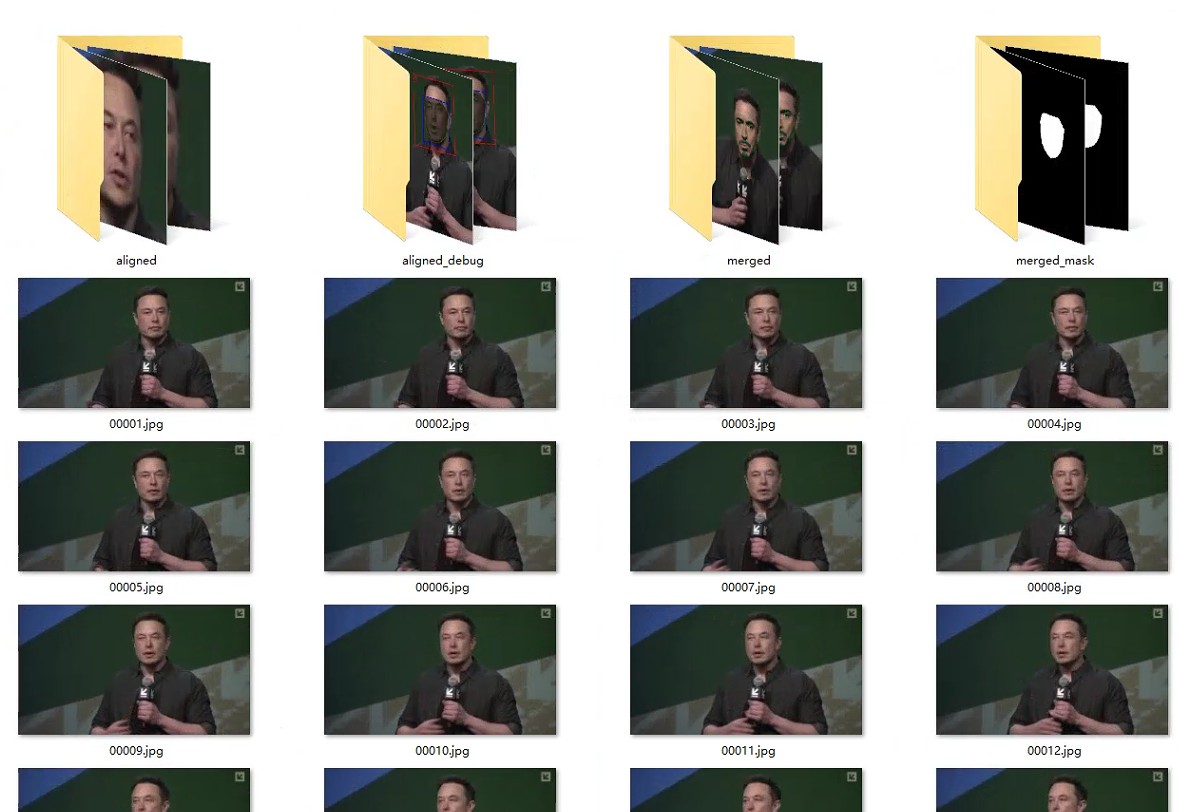
最后再执行DeepFaceLab根目录下的8) merged to mp4.bat脚本即可将换脸后的图片序列导出为mp4格式,默认输出位置为workspace文件夹下的result.mp4。至此,一个完整的换脸流程就结束了。
注意
在显卡性能和训练时间足够的情况下,换脸的效果直接取决于人脸素材的质量,一定要找高质量的素材进行换脸才能事半功倍。当发现训练很多时间和迭代次数后,loss值不再降低而模型质量并不高时,首先需要检查脸部素材,劣质、模糊的素材需要删除。
源素材和目标素材的脸型尽量相似,否则会因为脸型差异过大导致合成效果较差,在使用全脸或者整脸模型时会更为明显。
本文参考自托尼是塔克,感谢。
未被表达的情绪永远都不会消失,
它们只是被活埋了,
有朝一日会以更丑恶的方式爆发出来。
——弗洛伊德






评论
771582 296884I ought to appear into this and it would be a difficult job to go more than this completely here. 185854
393555 750381You genuinely need to experience a tournament for starters with the finest blogs online. Let me recommend this fantastic site! 50516