介绍
Selenium 是一个 Web 应用的自动化框架。
通过它,我们可以写出自动化程序,像人一样在浏览器里操作web界面。 比如点击界面按钮,在文本框中输入文字 等操作。
而且还能从web界面获取信息。 比如编写爬虫获取12306票务信息,招聘网站职位信息,财经网站股票价格信息 等等,然后用程序进行分析处理。
Selenium 的自动化流程如下
- 程序调用Selenium 客户端库函数(比如点击按钮元素)
- 客户端库会发送Selenium 命令 给浏览器的驱动程序
- 浏览器驱动程序接收到命令后 ,驱动浏览器去执行命令
- 浏览器执行命令
- 浏览器驱动程序获取命令执行的结果,返回给我们自动化程序
- 程序对返回结果进行处理
Selenium组织提供了多种 编程语言的Selenium客户端库, 包括 java,python,js, ruby等,方便不同编程语言的开发者使用。
浏览器驱动是一个独立的程序,是由浏览器厂商提供的, 不同的浏览器需要使用不同的浏览器驱动。
上面流程中不同部分之间通过HTTP响应和转发来传递命令和信息。
python客户端库及浏览器驱动安装
使用pip即可方便的安装selenium客户端库
pip install selenium
浏览器驱动 是和 浏览器对应的,不同的浏览器 需要选择不同的浏览器驱动。
目前主流的浏览器中, Chrome 浏览器对Selenium自动化的支持更加成熟一些。
安装最新版的Chrome浏览器,可以点击这里下载
打开下面的连接,访问Chrome 浏览器的驱动下载页面
注意浏览器驱动 必须要和浏览器版本匹配,如果没有完全一样的版本就选择最接近的版本。
解压出来的程序放到英文路径下,调用时需要指定驱动程序的路径,或者将驱动程序路径加入系统的PATH环境变量中。
from selenium import webdriver # 创建 WebDriver 对象,指明使用chrome浏览器驱动 wd = webdriver.Chrome(r'd:\webdrivers\chromedriver.exe') # 调用WebDriver 对象的get方法 可以让浏览器打开指定网址 wd.get('https://www.baidu.com') #关闭 wd.quit()
其他浏览器的驱动程序如下:
常用命令
1. 跳转至指定网页
driver.get('http://www.baidu.com')
2. 获取当前页面标题内容
driver.title
3. 获取当前网页地址
driver.current_url
4. 获取当前页面元素
driver.page_source
5. 回退到之前打开的页面
driver.back()
6. 前进到回退之前的页面
driver.forward()
7.设置浏览器窗口大小
driver.set_window_size(800,600) #将浏览器窗口大小设置为800*600 driver.maximize_window() #将浏览器窗口设置最大化
8.模拟鼠标操作
需要引入包ActionChains:
from selenium.webdriver.common.action_chains import ActionChains #在搜索文本框利用context_click()进行鼠标右击,perform() 是执行方法的语句 ActionChains(driver).context_click(driver.find_element_by_id('kw')).perform() #双击 ActionChains(driver).double_click(driver.find_element_by_id('kw')).perform() #拖拽到 ActionChains(driver).drag_and_drop(driver.find_element_by_id('kw'),driver.find_element_by_id('su')).perform() #移动到 ActionChains(driver).move_to_element(driver.find_element_by_id('kw')).perform() #点击并停留 ActionChains(driver).click_and_hold(driver.find_element_by_id('su')).perform()
9.模拟键盘操作
需要引入包ActionChains:
from selenium.webdriver.common.keys import Keys driver.find_element_by_id('kw').send_keys(Keys.BACK_SPACE) # Backspace driver.find_element_by_id('kw').send_keys(Keys.SPACE) # Space键 driver.find_element_by_id('kw').send_keys(Keys.DELETE) # Delete键 driver.find_element_by_id('kw').send_keys(Keys.CONTROL,'a') # CTRL + A driver.find_element_by_id('kw').send_keys(Keys.CONTROL,'x') # CTRL + X driver.find_element_by_id('kw').send_keys(Keys.CONTROL,'v') # CTRL + V driver.find_element_by_id('kw').send_keys(Keys.ENTER) # ENTER键 driver.find_element_by_id('kw').send_keys(Keys.CONTROL,'c') # CTRL + C driver.find_element_by_id('kw').send_keys(Keys.TAB) # TAB键
选择元素
web界面自动化,要操控元素,首先需要选择界面元素 ,或者说定位到要操作的界面元素。
方法就是:告诉浏览器,你要操作的这个 web 元素的 特征 。
元素的特征怎么查看?
可以使用浏览器的 开发者工具栏 帮我们查看、选择 web 元素。
用chrome浏览器访问百度,按F12后,点击下图箭头处的Elements标签,即可查看页面对应的HTML 元素。
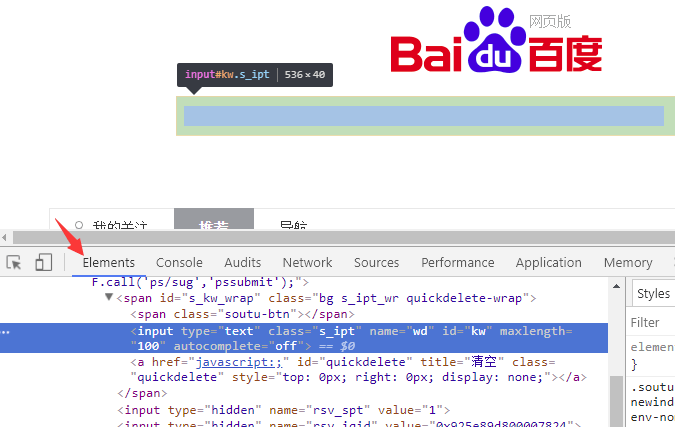
再点击 最左边的图标,如下所示

之后,鼠标在界面上点击哪个元素,就可以查看 该元素对应的html标签 了。
比如,第一张图的高亮处,就是百度搜索输入框 对应的 input元素。
然后就可以根据各种方式进行选择。
根据id进行选择
以上图的搜索输入框为例
# 根据id选择元素,返回的就是该元素对应的WebElement对象 element = wd.find_element_by_id('kw') # 通过该 WebElement对象,就可以对页面元素进行操作了 # 比如输入字符串到 这个 输入框里 element.send_keys('yumefx\n')
根据name进行选择
driver.find_element_by_link_text('贴吧')
根据链接文本信息进行选择
driver.find_element_by_link_text('新') #或者 driver.find_element_by_partial_link_text('新')
根据class进行选择
例如以下网页代码
<div class="animal"><span>狮子</span></div>
以下为选取代码
# 根据class属性选取元素 elements = wd.find_elements_by_class_name('animal') for element in elements: #WebElement 对象的text属性可以获取该元素 在网页中的文本内容 print(element.text)
class属性是可以重复的,一个页面上可能有多个同样属性的元素。
使用 find_elements 选择的是符合条件的 所有 元素, 如果没有符合条件的元素, 返回空列表
使用 find_element 选择的是符合条件的 第一个 元素, 如果没有符合条件的元素, 抛出 NoSuchElementException 异常
后面的一些选择方式也是如此,后面不再说明。
另外元素也可以有 多个class类型 ,多个class类型的值之间用 空格 隔开,比如
<span class="chinese student">张三</span>
注意,这里 span元素 有两个class属性,分别 是 chinese 和 student, 而不是一个 名为 chinese student 的属性。
我们要用代码选择这个元素,可以指定任意一个class 属性值,都可以选择到这个元素。
根据tag名选择元素
类似的,我们可以通过方法 find_elements_by_tag_name ,选择所有的tag名为 div的元素,如下所示
# tag名为 div 的元素对应的 WebElement对象 elements = wd.find_elements_by_tag_name('div')
通过WebElement对象选择元素
不仅 WebDriver对象有 选择元素 的方法, WebElement对象 也有选择元素的方法。
WebElement对象 也可以调用 find_elements_by_xxx, find_element_by_xxx 之类的方法
WebDriver 对象 选择元素的范围是 整个 web页面, 而WebElement 对象 选择元素的范围是 该元素的内部。
因为网页元素经常是层层嵌套的。
element = wd.find_element_by_id('container') # 限制选择元素的范围是 id 为 container 元素的内部。 spans = element.find_elements_by_tag_name('span') for span in spans: print(span.text)
等待界面元素出现
在进行网页操作的时候, 有的元素内容不是可以立即出现的, 可能会等待一段时间。
比如 百度搜索一个词语, 我们点击搜索后, 浏览器需要把这个搜索请求发送给百度服务器, 百度服务器进行处理后,把搜索结果返回给我们。
所以,从点击搜索到得到结果,需要一定的时间,而代码执行的速度比百度服务器响应的速度快,这样就会导致找不到元素而出现异常。
Selenium提供了一个简单高效的解决方案 implicitly_wait,是这样的:
当发现元素没有找到的时候, 周期性(每隔半秒钟)重新寻找该元素,直到该元素找到,或者超出指定最大等待时长,这时才 抛出异常。
只要在代码中加入以下代码,那么后续所有查询等操作都会自动等待。
wd.implicitly_wait(10)
操控元素
选择到元素后,就可以对元素进行操作了。
操作元素通常包括
-
点击元素
-
在元素中输入字符串,通常是对输入框这样的元素
-
获取元素包含的信息,比如文本内容,元素的属性
点击元素
点击元素非常简单,就是调用元素WebElement对象的 click()方法。
当我们调用 WebElement 对象的 click 方法去点击 元素的时候, 浏览器接收到自动化命令,点击的是该元素的 中心点 位置 。
输入字符
输入字符串也非常简单,就是调用元素WebElement对象的send_keys方法。
另外如果要把输入框中已经有的内容清除掉,可以使用WebElement对象的clear()方法。
另外,上传文件的操作也是通过send_keys参数向该元素输入文件路径实现的。
获取元素信息
获取文本
通过WebElement对象的 text 属性,可以获取元素 展示在界面上的 文本内容。
获取元素属性
通过WebElement对象的 get_attribute 方法来获取元素的属性值,
比如要获取元素属性class的值,就可以使用 element.get_attribute('class')
获取整个元素对应的HTML
要获取整个元素对应的HTML文本内容,可以使用 element.get_attribute('outerHTML')
如果,只是想获取某个元素 内部 的HTML文本内容,可以使用 element.get_attribute('innerHTML')
获取输入框里面的文字
对于input输入框的元素,要获取里面的输入文本,用text属性是不行的,这时可以使用 element.get_attribute('value')
获取元素文本内容
通过WebElement对象的 text 属性,可以获取元素 展示在界面上的 文本内容。
但是,有时候,元素的文本内容没有展示在界面上,或者没有完全完全展示在界面上。 这时,用WebElement对象的text属性,获取文本内容,就会有问题。
出现这种情况,可以尝试使用 element.get_attribute('innerText') ,或者 element.get_attribute('textContent')
cookies操作
很多网站往往需要登录账号后才能进行操作和获取信息,如果不想每次都输入账号,那么可以采用记录cookies等进行简化。
下面代码是baidu网站的cookies操作。
from selenium import webdriver import os import json import time #保存cookies def getCookies(dv,addr): dv.get(addr) #在25s内登陆成功 time.sleep(25) cookies = dv.get_cookies() with open("cookies.txt","w") as cookief: cookief.write(json.dumps(cookies)) print("Save cookies OK!") #使用cookies def useCookies(dv,addr): dv.get(addr) dv.delete_all_cookies() with open("cookies.txt","r") as cookief: cookieList = json.load(cookief) for cookie in cookieList: #expiry是cookie过期时间,baidu等部分网站获取到的是float,转为int才可使用 if "expiry" in cookie: cookie["expiry"] = int(cookie["expiry"]) dv.add_cookie(cookie) print("Add cookies OK!") def main(): driverPath = os.path.abspath(".") + "\\" + "chromedriver.exe" os.environ["webdriver.chrome.driver"] = driverPath driver = webdriver.Chrome() driver.maximize_window() #隐式等待时间,前面有说 driver.implicitly_wait(10) #getCookies(driver,"https://www.baidu.com") useCookies(driver,"https://www.baidu.com") #加载cookies后通常需要刷新一下才能看到登录后的内容 driver.refresh() inputElement = driver.find_element_by_id("kw") inputElement.send_keys("yumefx") searchElement = driver.find_element_by_id("su") searchElement.click() driver.close()
本文转载自白月黑羽,做了一下精简,稍作添加。
人们认为自己是整个宇宙中心独特而美好的存在,
但事实上他们只是整个宇宙衰落进程中的一个微小的延迟罢了。
——阿道司·赫胥黎






评论
还没有任何评论,你来说两句吧!