前言
最早是在果壳的《这下,你的老婆也可以变成3D的了》这篇文章中看到了这个项目3D-Photo-Inpainting,通过深度学习对普通的2D图片进行内容识别分层并自动修补,再通过虚拟摄像机的移动生成一段可以小幅度移动视角的3D照片。
官网的展示效果如下:

效果可以说非常惊艳,这么好的效果,当然要在我屯的图片中试试了。
在线使用
在官网页面的Links部分,提供了github链接和Colab链接,其中Colab是谷歌提供的云平台,可以免费在线学习和测试各种深度学习框架。
优点是可以白嫖谷歌的CPU和GPU,很方便地与谷歌云盘进行链接,安装各种环境和包的速度很快;缺点是有时间限制,用几个小时可能就会自动断掉,并且配置的好的环境不能保存,每次使用都需要重新部署。
首先因为是谷歌的服务,网络问题懂的都懂,在打开Colab链接后,是下面这样的界面,先点击最上面的复制到云端硬盘的按钮,将该脚本复制到自己的谷歌云盘中,这样下次使用时打开自己的谷歌云盘就能直接进入该脚本。
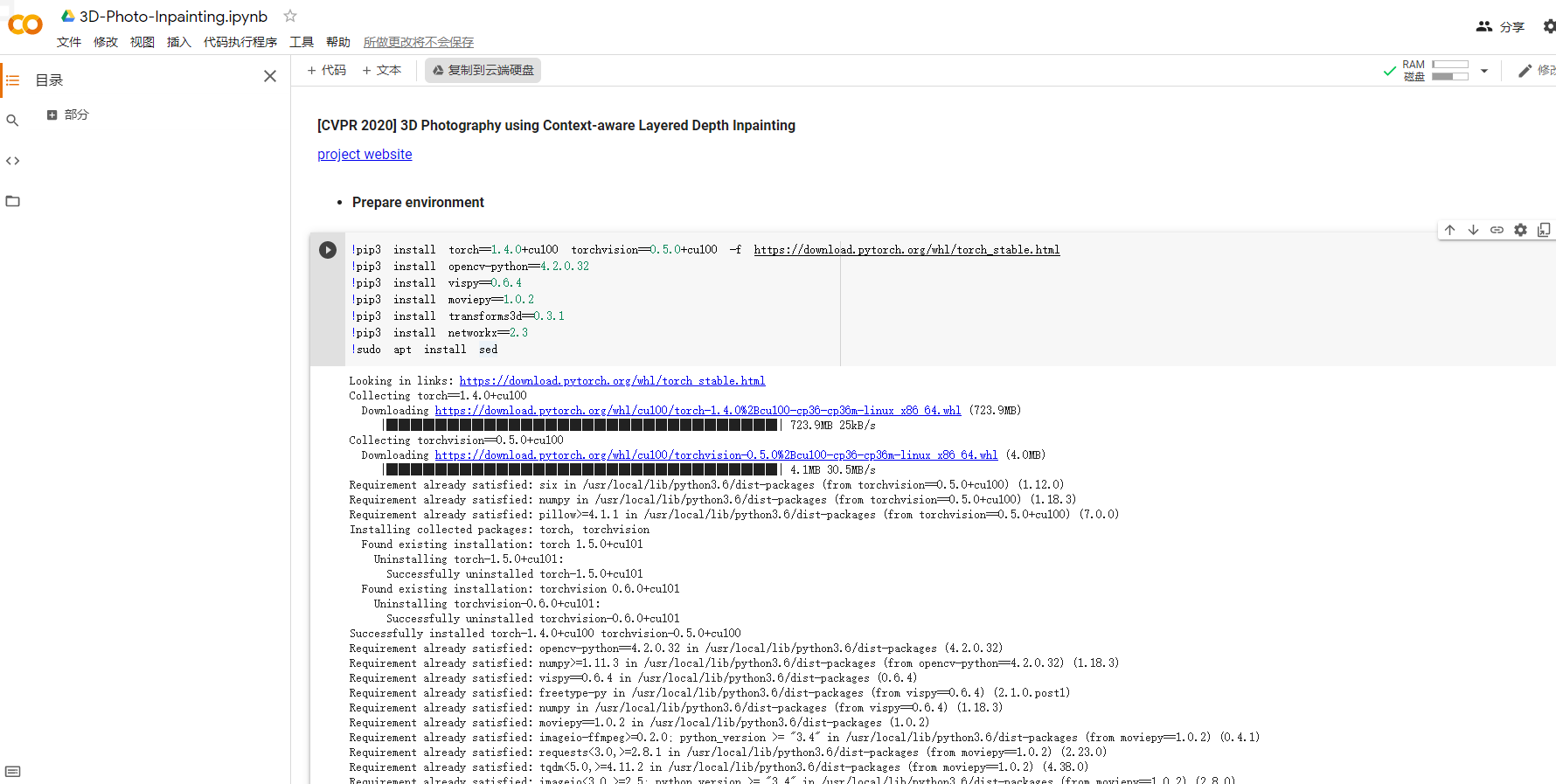
然后从下方每一段代码处找到左侧的运行按钮,按顺序点击运行按钮,等待环境部署完毕。
在运行upload段代码后,下方会出现选择文件的按钮,这是可以点击该按钮上传想要3D化的jpg图片,这一代码段可以运行多次,上传多张图片进行处理。
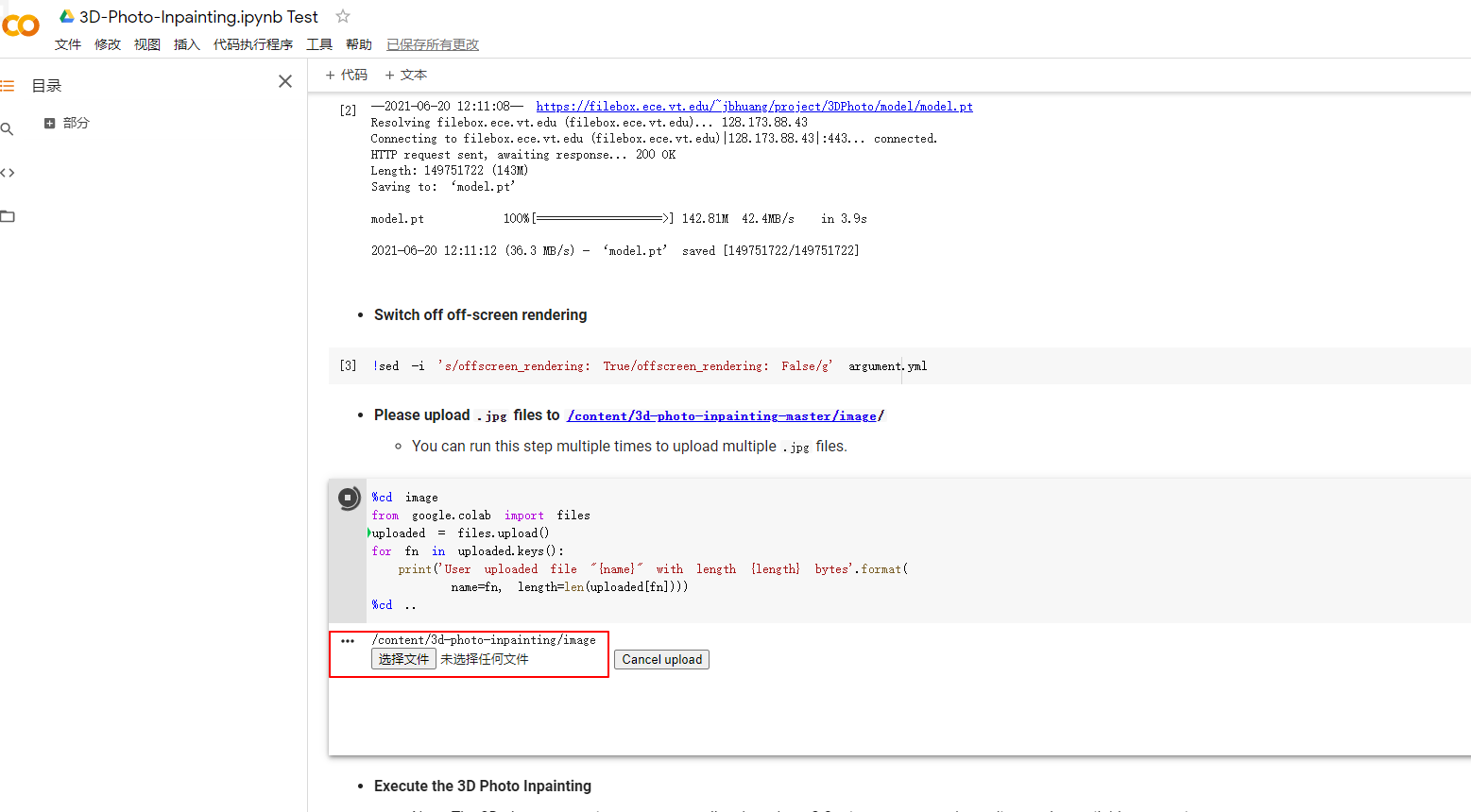
上传后的图片会出现在image目录中,可自行删除不需要的图片。
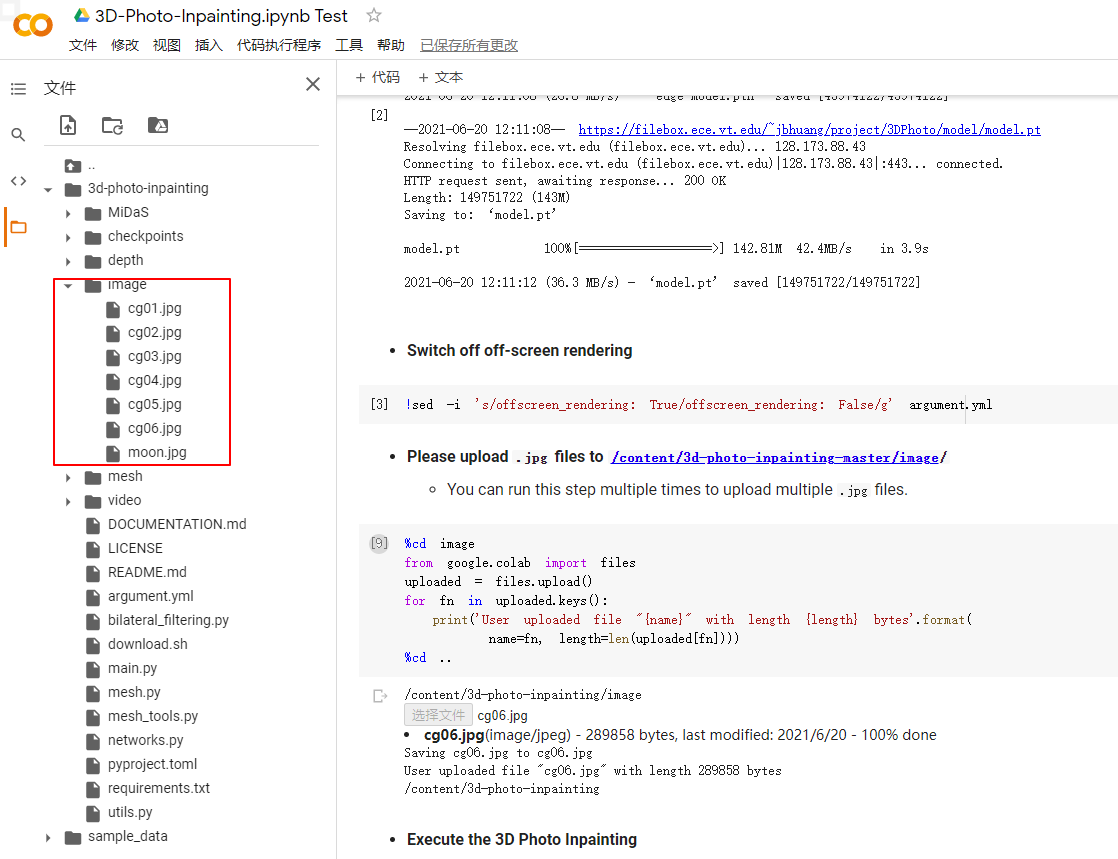
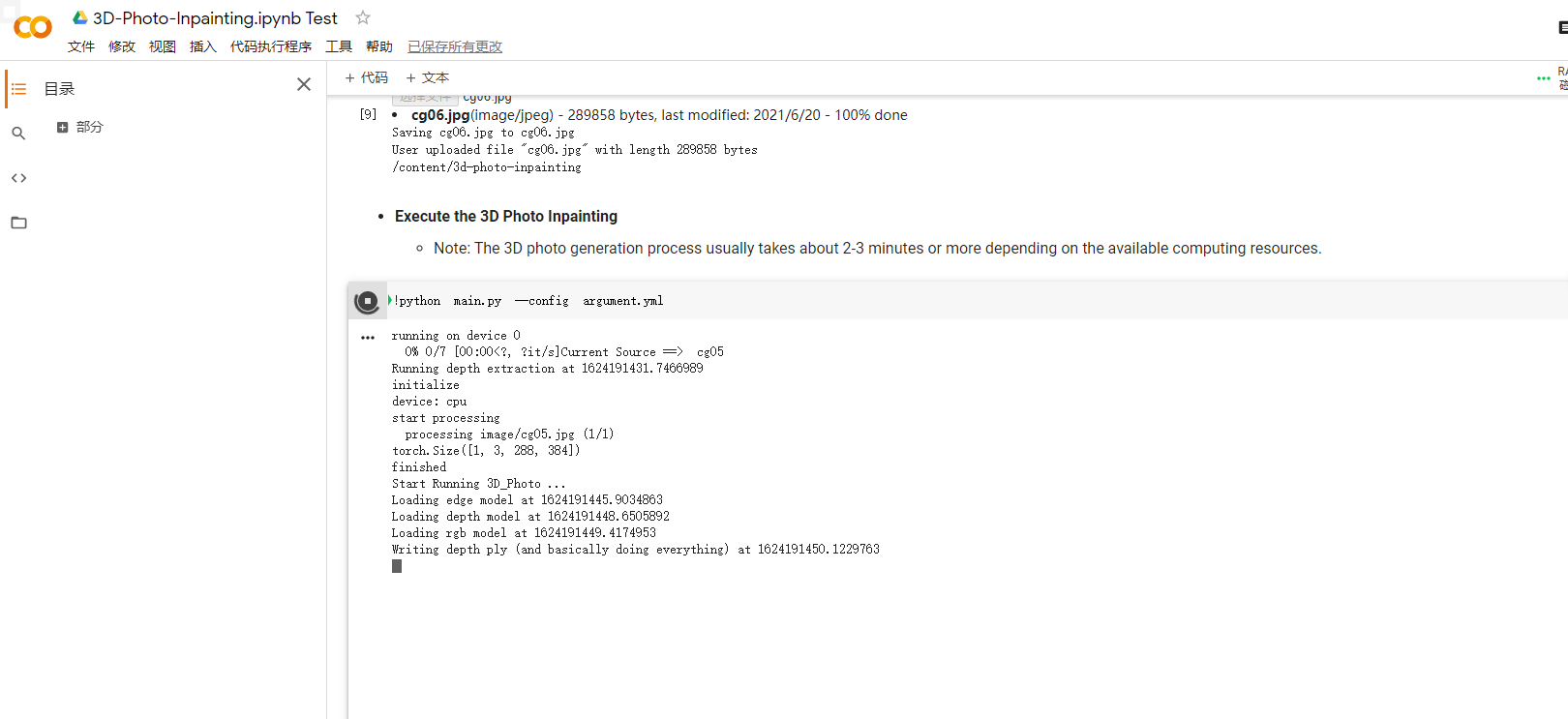
上传完成后运行最后一段main.py的代码,就会自动开始计算并生成视频,等待时间会较长。
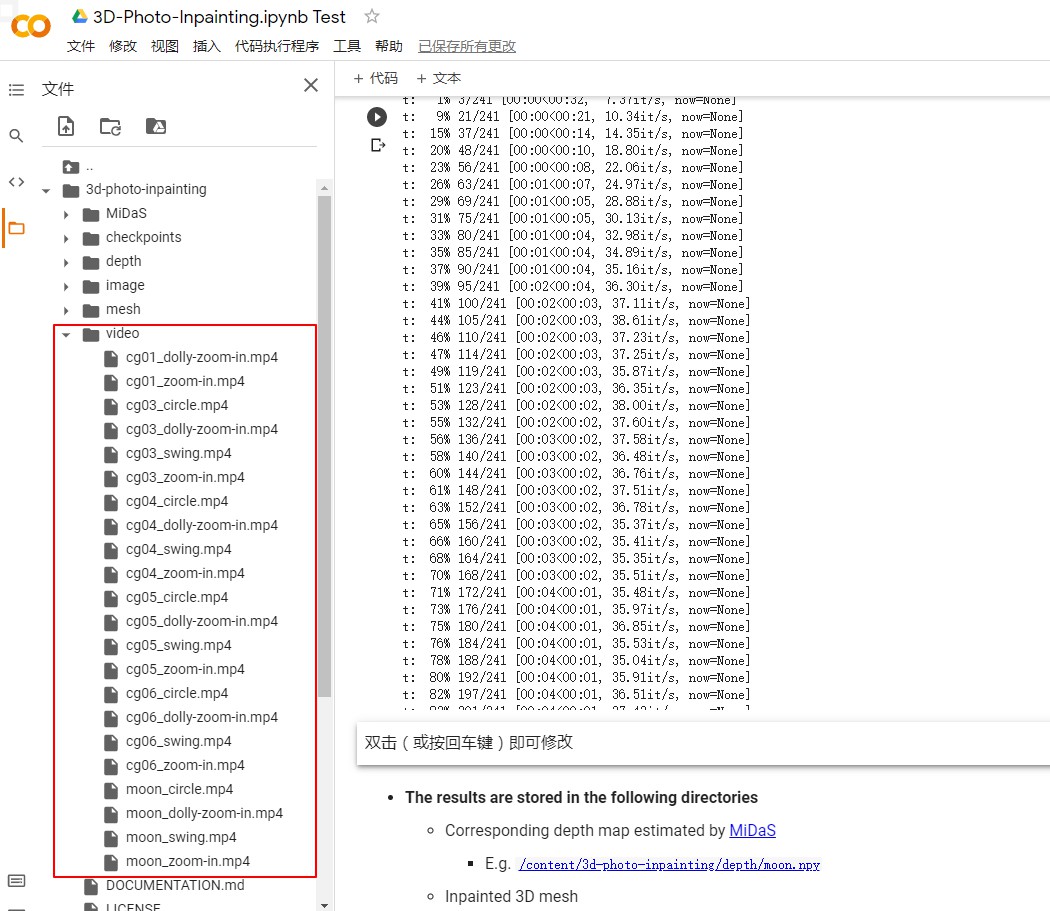
最终得到的视频在左侧的video目录下,可直接点击下载查看。
生成的效果如下。



本地使用
部署环境
3d-photo-inpainting项目需要的运行环境为Python3.7、PyTorch 1.4.0,前者很简单,后者的安装需要确认自己的系统以及显卡型号的CUDA版本(记得更新显卡驱动),如果显卡不支持CUDA,则只能使用CPU模式计算效率会很低。
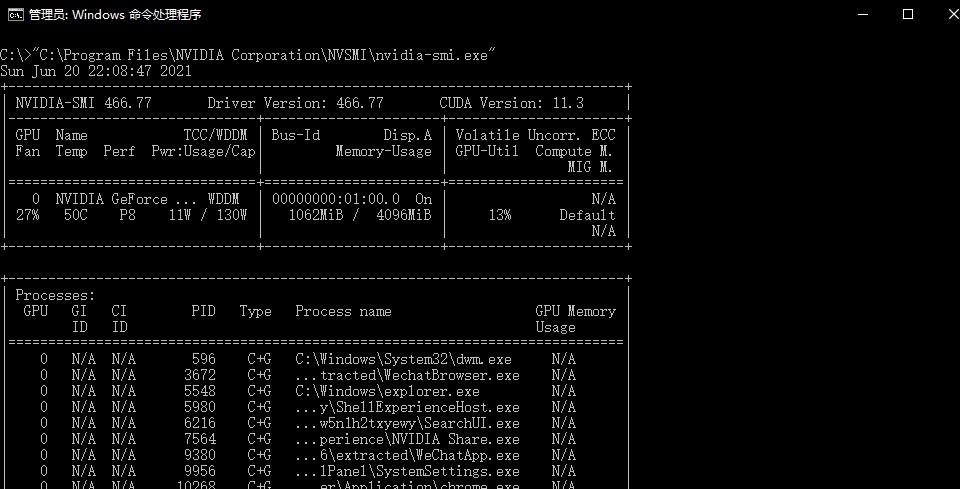
查看Windows系统的CUDA版本可以在CMD中运行以下工具。
C:\Program Files\NVIDIA Corporation\NVSMI\nvidia-smi.exe
CMD中打印的信息中CUDA Version后面的就是支持的CUDA版本。
然后到PyTorch的官方网站选择适合的版本复制部署命令在CMD中执行,如果需要较早的PyTorch版本可以查看这里。
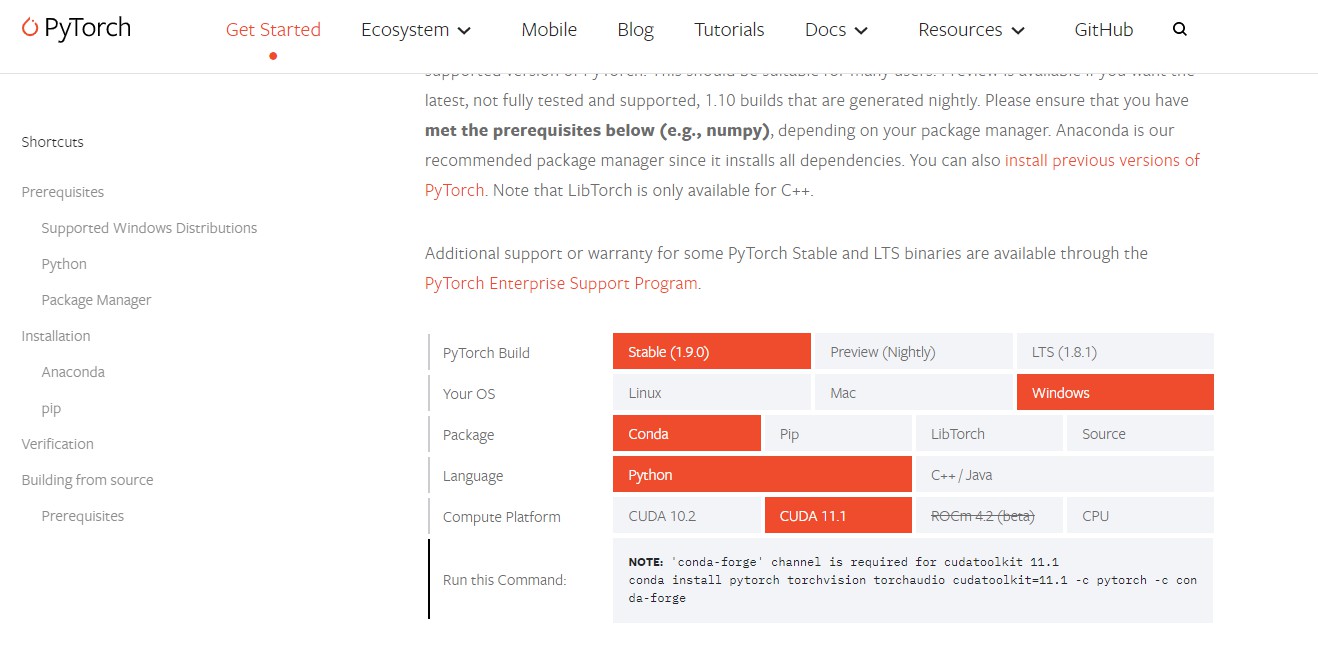
由于PyTorch包体积很大,安装会很慢,耐心等待安装成功吧。
下载源码和训练模型
先使用git将官方仓库克隆到本地,或者直接在网页下载zip包并解压。
git clone git@github.com:vt-vl-lab/3d-photo-inpainting.git
接着根据下载源码中的download.sh脚本的内容下载四个训练模型,在项目根目录新建checkpoint文件夹,再将下载好的pth文件放到checkpoint文件夹中。
最后将要转换的图片放到image目录下,在CMD中执行以下Python命令。
cd ../3d-photo-inpainting python main.py --config argument.yml
最后等待计算完成即可。
argument.yml这个配置文件中记录了一些参数,可以用来控制视频大小和镜头运动等,可根据需要自行修改。
实验后发现,对于图片的前后分层还是不够智能,在选择素材时尽量选择前景后景比较分明的图片,最后得到的效果会比较好。
到了这里,忽然有了一个想法,将喜欢的图片做成动态,再加上音乐,放到WallPaperEngine里,一张精致的动态壁纸不就完成了,不说了,我先去折腾了。
不是人有欲望,
而是人即欲望。
《我与地坛》
——史铁生






评论
746457 757686Fantastic beat ! I wish to apprentice whilst you amend your web site, how can i subscribe for a blog website? The account aided me a appropriate deal. I had been just a little bit acquainted of this your broadcast provided bright clear concept 471579